Clasificación de objetos#
¿Qué es la clasificación?#
En pocas palabras, la clasificación fenotípica se trata de categorizar objetos en diferentes grupos según sus características (también conocidas como medidas).
📏 ¿Cómo lo mido?
La clasificación fenotípica se puede realizar de diferentes maneras. Una forma de desglosar esto es mediante la clasificación no supervisada frente a la supervisada.
En la clasificación supervisada, un ser humano también brinda información sobre cómo deberían verse los diferentes grupos de objetos al proporcionar ejemplos representativos de cada grupo en un conjunto de datos de entrenamiento. Luego, la computadora aprende cómo asignar objetos a grupos, en función de sus medidas al probar modelos contra el conjunto de datos de entrenamiento de verdad del terreno.
Por ejemplo, podría clasificar células según un fenotipo visual y entrenar un clasificador de aprendizaje automático para derivar qué rangos de medición están asociados con diferentes clases. Esta es una clasificación supervisada porque una persona proporciona instrucciones sobre cuántas clases debe haber y ejemplos de cómo debe verse cada clase para que la computadora aprenda. Un ejemplo de esto podría ser anotar un subconjunto de células que se encuentran en diferentes etapas de la mitosis y entrenar un clasificador para usar sus etiquetas para encontrar otras células en esas etapas.
En la clasificación no supervisada, los objetos se agrupan en función de sus medidas, pero sin ninguna guía de arriba hacia abajo definida por humanos sobre cuántos grupos hay o cómo deberían ser los grupos.
Por ejemplo, podría medir cientos o miles de características de las células de muchos tratamientos, como es habitual en los experimentos de perfilado de células a gran escala. A continuación, puede dejar que la computadora agrupe las células en una cierta cantidad de grupos diferentes en función de tener medidas similares. Esta es una forma de agrupamiento no supervisado, donde observa qué grupos emergen de una computadora considerando solo sus medidas, y no las etiquetas de clase que imponemos como investigadores. Estos tipos de experimentos de agrupamiento pueden proporcionar resultados novedosos, pero también pueden ser más difíciles de interpretar. Consulte este protocolo24 para obtener más información.
⚠️ ¿Dónde pueden salir mal las cosas?
Las medidas válidas siguen siendo importantes La clasificación puede ser simple o compleja, pero los resultados siempre dependen de la validez de sus medidas. Por esta razón, todas las advertencias de las secciones de medición anteriores también se aplican aquí.
Las máquinas son perezosas Los clasificadores de aprendizaje automático no necesariamente van a aprender las características biológicamente relevantes que distinguen objetos de distintos grupos. Las características confusas, o características que varían con su fenotipo pero que no están biológicamente relacionadas con él, pueden limitar la utilidad de su clasificador y llevar a conclusiones incorrectas. Por ejemplo, si los médicos a menudo colocan reglas al lado de los lunares malignos y no al lado de los lunares benignos y tratan de entrenar un clasificador de aprendizaje automático para distinguir entre malignos y benignos, el modelo podría aprender a clasificar imágenes con reglas como malignos sin aprovechar ninguna de los las características relevantes de los lunares. Este es un ejemplo real 25. Si es posible, examinar en qué características se basa su modelo para clasificar objetos puede ser una forma de verificar esto. También es importante estandarizar la forma en que captura imágenes de sus diferentes clases de objetos e incluir un conjunto de entrenamiento lo suficientemente grande con imágenes con mucha variación. No querrá que todas sus células positivas provengan de muestras que tomó en imágenes en marzo y todas sus células negativas de muestras que tomó en imágenes en enero, por ejemplo.
Violación de suposiciones del modelo Si usa un clasificador de aprendizaje automático, los diferentes modelos vienen con diferentes suposiciones integradas. Si está empezando, puede ser difícil saber cuál elegir. Hay herramientas interactivas como CellProfiler Analyst 26 y Piximi que facilitan el entrenamiento de un clasificador, especialmente si no sabe programar.
Límites desordenados La mayoría de los métodos de clasificación supervisada, en los que el usuario asigna objetos a una puntuación o a un contenedor, en última instancia tratan cada contenedor como una entidad totalmente separada; la biología rara vez es tan ordenada. Por ejemplo, un clasificador supervisado para la fase del ciclo celular debe asignar una célula a una fase, pero, de hecho, la progresión a través del ciclo celular no es un proceso parecido a un interruptor perfecto, como se puede visualizar mediante mediciones de células individuales (coloreadas por su clase dada por un observador humano). Es posible que se necesiten métodos más sofisticados para clasificar fenotipos más continuos.
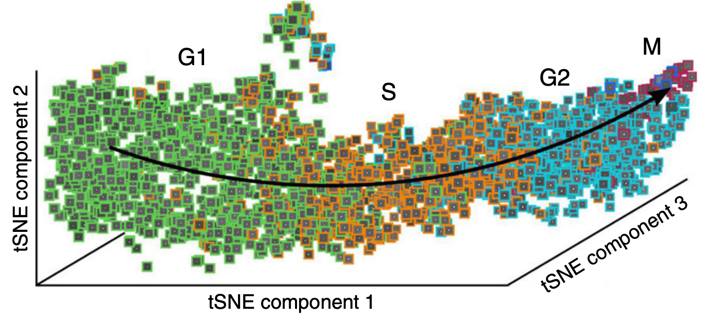
Figura 7 La división estricta en clases supervisadas puede ser complicada para los procesos biológicos continuos. Adaptado de Eulenberg, P., Köhler, N., Blasi, T. et al. Reconstruir el ciclo celular y la progresión de la enfermedad mediante el aprendizaje profundo. Nat Commun 8, 463 (2017) 27#
📚🤷♀️ ¿Dónde puedo obtener más información?
📄 Estrategias de análisis de datos para perfiles celulares basados en imágenes 28
📄 Puntaje de diversas morfologías celulares en pantallas basadas en imágenes con retroalimentación iterativa y aprendizaje automático 29
🎥 Serie de videos de iBiology: Medición y clasificación de fenotipos
📄 Interpretación de perfiles basados en imágenes usando agrupamiento de similitud y visualización de células únicas 24